

Chińskie modele językowe wywołały w ostatnich dniach prawdziwe trzęsienie ziemi na rynku AI. Najpierw DeepSeek, teraz nowe modele Qwen2.5 od Alibaby. Każda z tych premier to nie tylko technologiczny krok naprzód, ale również poważny cios dla konkurencji zza oceanu.
Spadki na giełdzie wywołane doniesieniami z Chin jasno pokazują, że inwestorzy zaczęli kwestionować przyszłość dominacji amerykańskich firm w tej branży. Czy amerykańscy giganci sztucznej inteligencji mogą spać spokojnie? Nowe modele, takie jak Qwen2.5-7B-Instruct-1M i Qwen2.5-14B-Instruct-1M, wprowadzają nie tylko innowacje w postaci pracy z kontekstami do miliona tokenów, ale także redefiniują oczekiwania wobec tego, co mogą oferować publicznie dostępne modele.
Dlaczego okno kontekstowe w modelach LLM jest takie ważne?
Standardowe modele językowe zazwyczaj operują na kontekstach o ograniczonej długości, co bywa problematyczne przy analizie obszernych dokumentów. Qwen2.5-7B i Qwen2.5-14B wychodzą naprzeciw tym wyzwaniom, umożliwiając przetwarzanie ogromnych ilości danych w jednym podejściu.
Jak działają te modele? Zastosowano technologię rzadszej uwagi (sparse attention), która skupia się jedynie na najistotniejszych fragmentach kontekstu. W efekcie przetwarzanie danych jest nawet trzy do siedmiu razy szybsze niż w przypadku tradycyjnych metod, a wyniki mogą sięgać do 8 tysięcy tokenów na jedno zapytanie.
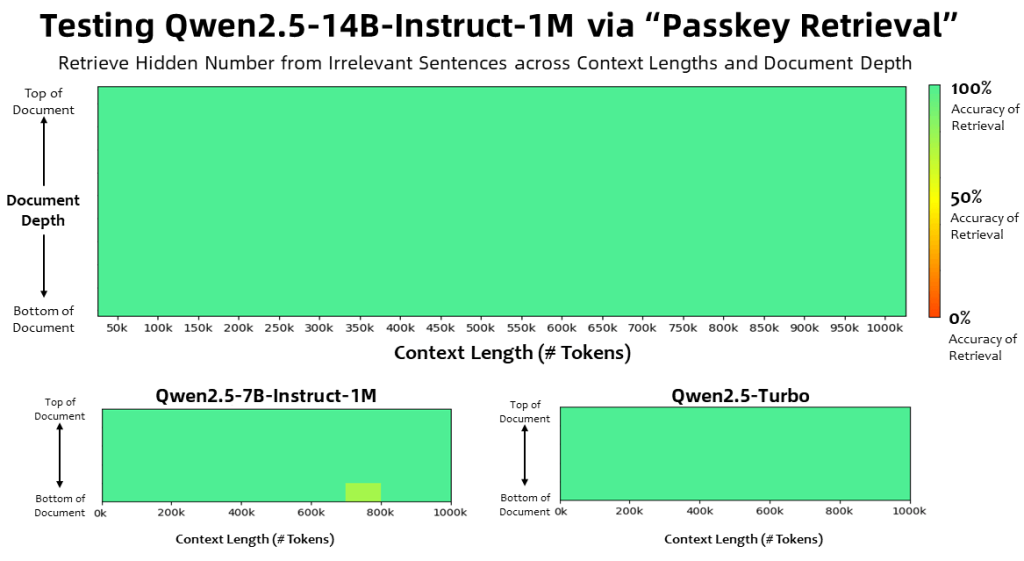
Podczas testów Qwen2.5-14B oraz wersja Turbo modelu osiągnęły doskonałą dokładność w wyszukiwaniu ukrytych liczb w długich dokumentach. Mniejszy model, Qwen2.5-7B, również poradził sobie świetnie, choć zdarzały się drobne błędy. Warto jednak zaznaczyć, że testy te w większym stopniu mierzyły zdolności wyszukiwania informacji (podobne do funkcji Ctrl+F), niż zrozumienia głębszego sensu tekstu.
Jak wypada Qwen na tle systemów RAG?
Systemy Retrieval-Augmented Generation (RAG), które podczas analizy korzystają z zewnętrznych baz danych, wciąż pozostają bardziej precyzyjne przy pracy z mniejszymi oknami kontekstowymi, sięgającymi 128 tys. tokenów. Modele z oknami o długości miliona tokenów, takie jak Qwen2.5, oferują jednak większą elastyczność i prostotę obsługi, co może być decydujące w wielu przypadkach użytkowych.
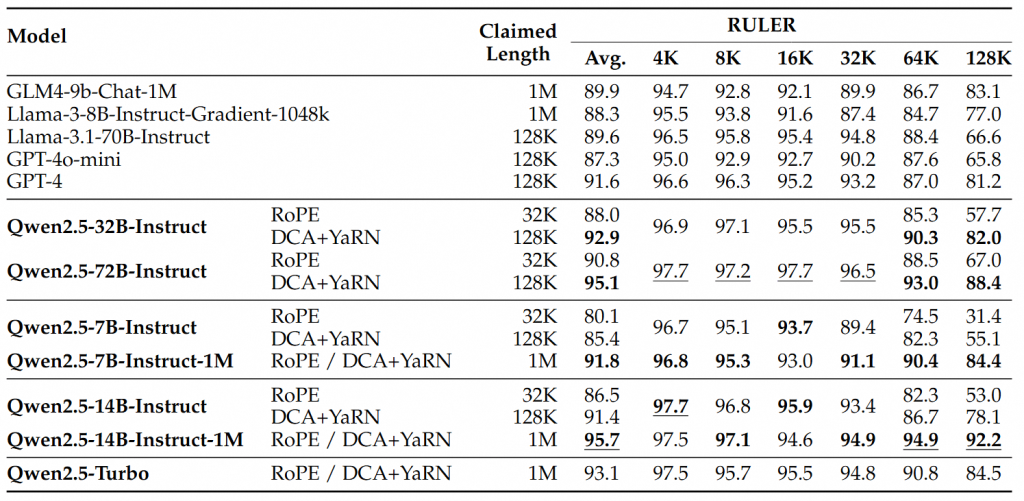
W testach takich jak RULER, LV-Eval czy LongbenchChat modele Qwen2.5 wyraźnie przewyższyły swoich rywali z oknami 128K, szczególnie przy sekwencjach dłuższych niż 64 tys. tokenów. Qwen2.5-14B osiągnęł nawet ponad 90 punktów w RULER – to pierwszy taki wynik w serii Qwen, pokonujący między innymi GPT-4o mini w wielu zestawach danych.
Co ważne, modele Qwen nie tracą na efektywności w przypadku krótszych tekstów, gdzie ich wyniki są porównywalne z modelami o mniejszych oknach kontekstowych.
Użytkownicy mogą przetestować Qwen2.5 za pośrednictwem Qwen Chat – interfejsu podobnego do ChatGPT, lub na platformie Hugging Face, gdzie dostępne są również inne modele Alibaby. Warto zwrócić uwagę, że Alibaba, wraz z innymi chińskimi firmami, takimi jak Deepseek, rzuca wyzwanie amerykańskim dostawcom, oferując podobne możliwości za niższe koszty.
Źródło: The-decoder
Zdjęcie: x.com