

Naukowcy z Meta i Uniwersytetu Kalifornijskiego w San Diego opracowali nowatorską metodę dla modeli językowych, zwaną „Coconut” (Chain of Continuous Thought). Pozwala ona sztucznej inteligencji myśleć w przestrzeni latentnej zamiast w naturalnym języku, co przynosi liczne korzyści w porównaniu z tradycyjnymi podejściami.
Czym jest przestrzeń latentna?
Przestrzeń latentna to abstrakcyjna reprezentacja danych w modelach sztucznej inteligencji. Zamiast pracować z bezpośrednimi danymi, takimi jak tekst czy obrazy w ich pierwotnej formie, modele przekształcają je w wielowymiarowe wektory w ukrytej przestrzeni. W przestrzeni tej cechy danych są reprezentowane w sposób bardziej zrozumiały dla modelu, co pozwala mu lepiej rozpoznawać wzorce, zależności czy różnice między danymi.
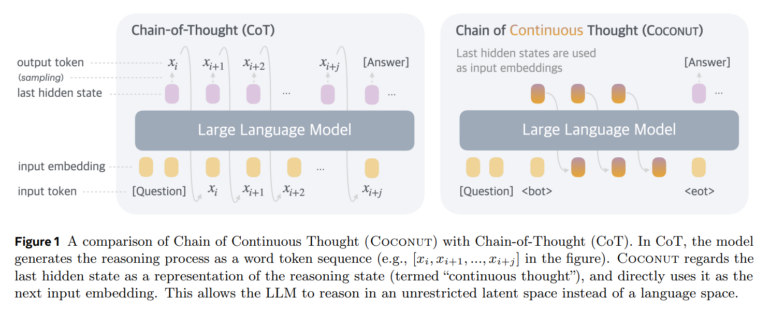
Metoda ta opiera się na pracy w stanie ukrytym modelu językowego (LLM) zamiast wyrażania myśli za pomocą słów. Jak wskazuje badanie, jest to rozwinięcie podejścia Chain-of-Thought (CoT), w którym modele przetwarzają zadania krok po kroku w języku naturalnym.
Jak działa Coconut?
Głównym założeniem Coconut jest eliminacja ograniczeń związanych z koniecznością wyrażania wszystkich etapów rozumowania za pomocą słów. Naukowcy zauważają, że wiele tokenów w naturalnym języku jest wykorzystywanych wyłącznie do zapewnienia spójności tekstu, co niekoniecznie wspomaga procesy logiczne i rozumowanie.
– Większość tokenów tekstowych służy głównie do zachowania spójności tekstu, a nie jest niezbędna dla rozumowania – tłumaczą badacze.
W przestrzeni latentnej model może przetwarzać wiele możliwych ścieżek myślowych jednocześnie, stopniowo eliminując nieprawidłowe opcje przed wygenerowaniem tokenów wyjściowych.
Lepsze wyniki w złożonych zadaniach
W testach Coconut porównano z tradycyjną metodą CoT w trzech typach zadań:
- Problemy matematyczne (GSM8k)
- Coconut osiągnął dokładność 34,1%, co jest niższym wynikiem niż CoT (42,9%), ale znacząco przewyższa bazowy poziom bez łańcuchów myśli (16,5%).
- Rozumowanie logiczne (ProntoQA)
- Coconut uzyskał dokładność 99,8%, pokonując CoT (98,8%).
- Zaawansowane planowanie (ProsQA)
- Coconut osiągnął wynik 97%, podczas gdy CoT tylko 77,5%.
Ponadto, Coconut zużywał znacznie mniej tokenów niż CoT: dla testu ProntoQA było to średnio 9 tokenów zamiast 92,5, a dla ProsQA średnio 14,2 tokenów zamiast 49,4. Pokazuje to, że metoda jest bardziej efektywna i precyzyjna w złożonych zadaniach logicznych.
Wyzwania w treningu Coconut
Pomimo imponujących wyników, metoda napotyka wyzwania podczas procesu treningowego. Standardowe metody szkolenia nie pozwalały modelowi skutecznie myśleć w przestrzeni latentnej. W badaniu wykorzystano wstępnie wytrenowany model GPT-2, a naukowcy opracowali wieloetapowy program treningowy. Stopniowo wprowadzano coraz więcej myśli w przestrzeni latentnej, redukując zależność od rozumowania językowego.
Potencjał na przyszłość
Zdaniem badaczy metoda Coconut otwiera nowe możliwości dla rozwoju systemów sztucznej inteligencji. – W licznych eksperymentach wykazaliśmy, że Coconut znacząco poprawia zdolności rozumowania modeli LLM – podsumowują autorzy. Szczególnie obiecująca jest zdolność systemu do niezależnego opracowywania wzorców myślowych przypominających algorytm wyszukiwania wszerz.
W przyszłości planowane jest szkolenie większych modeli językowych w oparciu o myśli w przestrzeni latentnej. Może to umożliwić rozszerzenie zdolności modelu na szerszy zakres zadań.
Źródło: The-decoder
Photo by Piotr Łaskawski on Unsplash